I started relying on ChatGPT in 2022, when my PI bought a premium account for the lab. I had used the free version in the past, but for $20 a month we gained early access to the latest models and never had to wait for server availability. It didn’t take very long for me to realize that this $20 was well spent.
I was an undergraduate student working in a dry lab, so using ChatGPT to help write and debug code significantly increased my productivity. When my code threw an error, ChatGPT would translate the confusing error message into concise recommendations. When I wanted to write a function to do a series of matrix manipulations, I no longer had to draw out the linear algebra by hand. And when it came time to plot, I could avoid googling for the umpteenth time how to change the size of my x-axis font or adjust the space between subplots. As a lab, we estimated that ChatGPT saved us 25% of our time. With ten lab members working forty-hour weeks, that $20 generated roughly 400 hours of work each month.
ChatGPT and other large language models (LLMs) are forms of generative AI that predict the next word in a sequence. When trained on vast amounts of text data—most of which is sourced from the internet—LLMs can answer questions, engage in conversation, and generate various types of content. Since 2022, the LLM market has expanded dramatically, with competition from companies like Anthropic and DeepMind spurring a technological arms race that continues to broaden the range of LLM applications available to consumers.
The Kronauer lab here at Rockefeller shares a premium account, and I witness my colleagues using it frequently. Many things are easier with ChatGPT, like plotting data and formatting figures, installing Python packages that have poor online documentation, summarizing a messy note from a seminar or conference, or editing an abstract.
I sometimes worry about providing ChatGPT information about my experimental results, as the model can learn from user data. These days, I almost exclusively use the “Temporary Chat” feature, which promises that the chat history will be deleted and never used to train future models.
I’m not here to proselytize using ChatGPT at work. Nonetheless, tools like ChatGPT are fundamentally changing the pace of work, including what we do at Rockefeller. Because of this, I think they merit serious consideration.
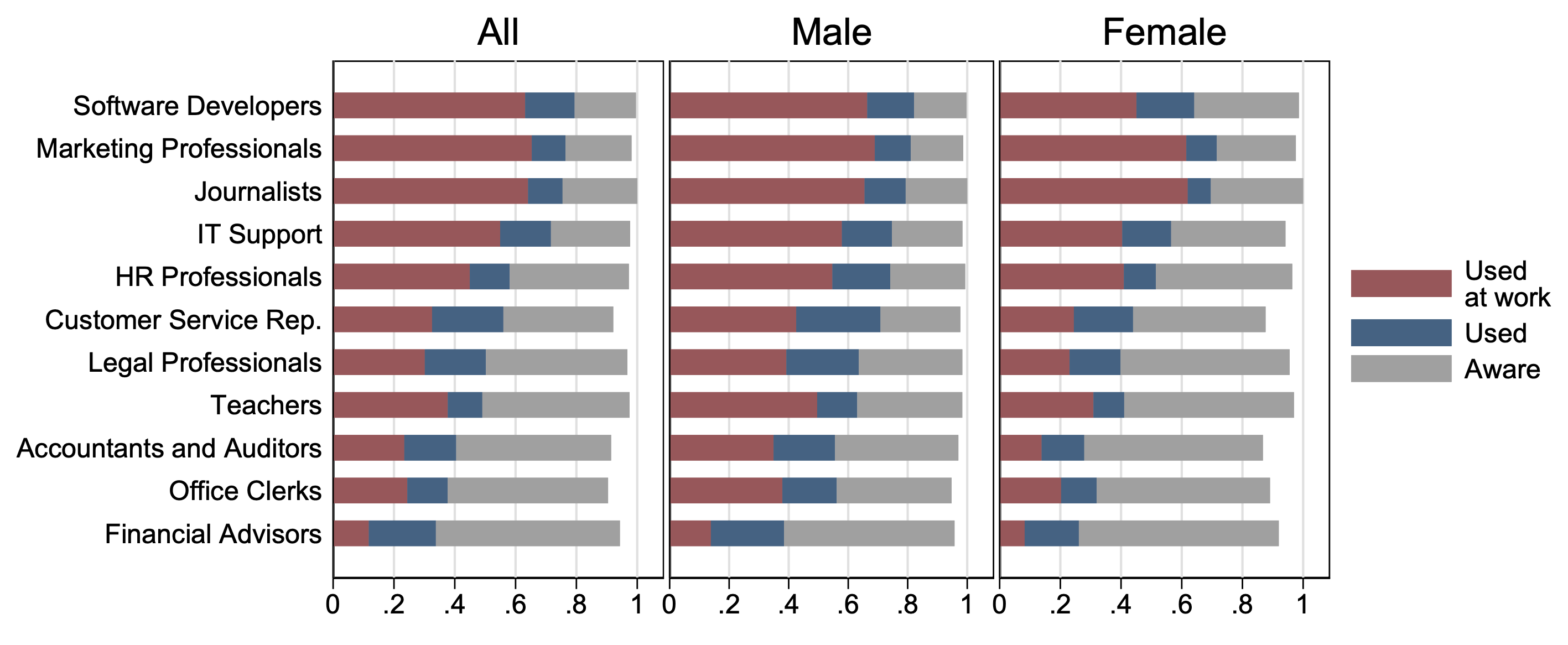
LLMs like ChatGPT are so new that the literature is sparse, but a recent publication from the University of Chicago that surveyed 100,000 workers in Denmark showed astoundingly high usage rates, with significant variation across employment sectors. Over half of the workers surveyed had used ChatGPT; of this fraction, 72% had used it at work. According to the study, this rapid uptake has been largely driven by “the individual decisions of workers to start using [ChatGPT], with many employers playing a passive or regressive role.”
Another survey of 1,018 materials scientists in industry R&D found that AI-assisted research resulted in 39% more patent filings and a doubling of research output from top scientists.
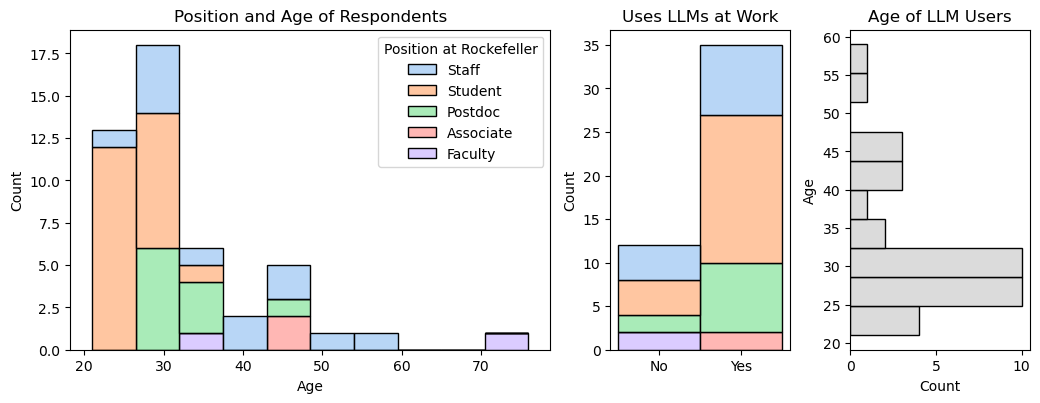
I figured that the prevalence of ChatGPT was not unique to my lab. To find out more, I collected anonymous survey responses from forty-seven students, postdocs, faculty, staff, and research associates at Rockefeller, of varying ages.
75% of respondents reported using LLMs at work. Of these people, 57% rely on LLMs for increased productivity or efficiency and 66% anticipate their use to increase over the next year. The sheer ubiquity of LLM usage, especially among older scientists, was striking. Neither age nor position was predictive of the frequency of LLM use, though that could change with a larger sample size.
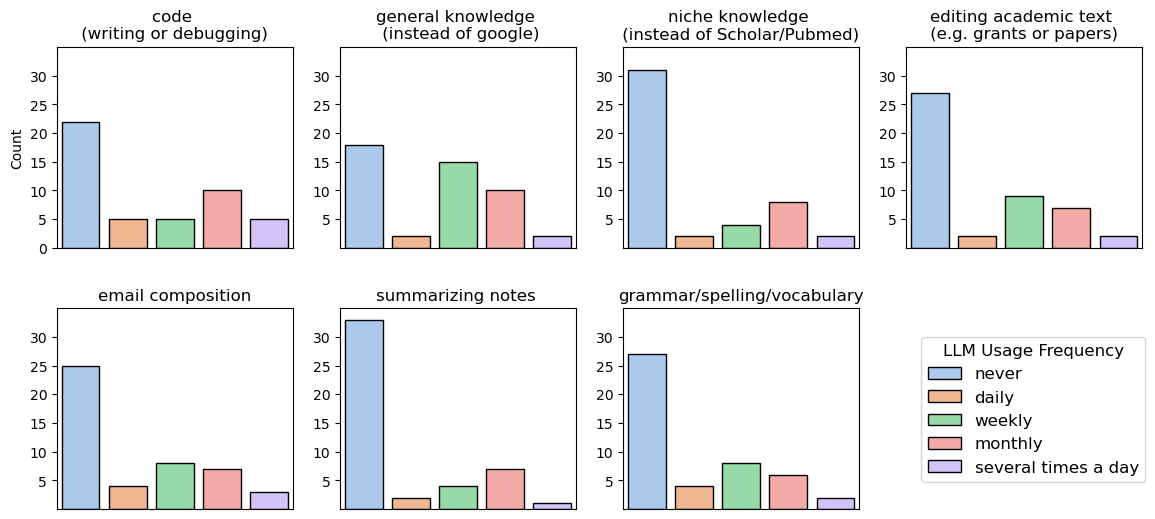
Interested in the specific use cases of LLMs, I surveyed the frequency with which respondents use LLMs for work-related tasks.
Only 15% of respondents claimed that they never used LLMs for any of these tasks. The most popular use cases were “general knowledge (instead of Google),” followed by “code (writing or debugging)” and “email composition.”
When asked if there are other use cases beyond those described, one participant emphasized the utility of “translating text into English and revising the grammar and style of text written by non-native speakers.” I neglected to include this use case in the survey, but I can imagine that ChatGPT is excellent for translating documents, emails, or even academic papers. Other scientists claimed to use LLMs to write protocols and design primers. I have found ChatGPT useful for optimizing simple protocols like RT-PCR, but I also remember arguing with ChatGPT over a stoichiometry mistake it refused to admit to making.
As scientists, we are trained to scrutinize new discoveries as well as new tools. However, it appears that LLMs have managed to slither their way into the everyday scientific toolkit without much resistance or cause for alarm. I am grateful for the utility of LLMs but am also aware that LLMs were not available to me during the bulk of my education, when they may have interfered with seminal learning milestones. When I consider the dangers of LLMs in research, several questions come to mind. Does reliance on these tools make us lazier scientists? Does it make our science more error-prone?
A minority (21%) of survey respondents were completely untroubled about the use of LLMs in research. No one brought up apocalyptic visions of Skynet or Hal 9000, but many respondents provided commentary on what concerns them. Some shared my belief that LLMs interfere with the learning process, such as one student who said, “Copy-and-pasting the code is way less conducive to my learning than the slower process of figuring it out from first principles.” Others were more concerned with “misinformation,” “data privacy,” and “regression to the mean.” One student said, “My philosophy with AI is ‘trust but verify.’ I worry that many people take output from LLMs at face value and leave out that verification.”
When asked about the situations in which LLMs provide inaccurate or inadequate answers, the most frequent complaints were about niche knowledge (n = 15) and inaccurate citations (n = 5). I have heard many people dismiss LLMs altogether for providing inaccurate citations, though competitors of ChatGPT like Perplexity AI and Notebook LM have attempted to remedy this flaw by providing references (DOI links) with each output.
Whereas scientists frequently cite tools like AlphaFold, citing or even acknowledging the use of LLMs remains unconventional. When asked whether LLMs should be cited, 64% of respondents responded in the affirmative, while 10% claimed it depends on the use case. “At [this] point LLMs are a modern Google. One doesn’t cite Google,” said one adamant participant. Citing LLMs is “paradoxical,” said another scientist. When I use ChatGPT to edit text that I already drafted or use Copilot to speed up my coding, I still feel ownership over the intellectual property. So should I cite it? Springer Nature declares that LLMs do not qualify as authors but should be referenced in the methods section for any “AI assisted copy editing.”
My data reflects a small sample size (forty-seven of roughly 2,000 Rockefeller employees) and may be prone to sampling bias, but it reflects the emerging ubiquity of LLMs in our everyday research activities. Many respondents demonstrated an encouraging awareness of the limitations and dangers of LLMs, recognizing that ChatGPT is primarily trained on data sourced from the internet, which is not immune to misinformation or disinformation.
Cornell has disseminated guidelines on the best practices for integrating AI into research activities, but Rockefeller could do more to educate us scientists on how to use these transformative tools responsibly.
For now, it is up to every individual to decide for themselves how they see LLMs fitting into their daily tasks. As scientists, we must be vigilant about separating fact from fiction. When we succumb to the ease of ChatGPT, we must not blindly accept it to the detriment of our scientific rigor.